Testing Apibara indexers
Apibara ships with a testing framework that makes testing indexers a joy. Traditionally, testing indexers requires a considerable time, so many teams skip this step. Apibara solves this by:
- Generating testing fixtures for you using actual data.
- Automatically running indexers on the testing fixtures and checking the output with known reference values.
This testing strategy is often called "snapshot testing". The idea is to generate snapshots of the test output and compare this value in successive test runs. One key difference of snapshot testing compared to other strategies is that the initial snapshot is generated by running the target code and assuming the output is correct. Your job as a developer is to check the output and adjust it if it's incorrect.
Generating tests
This guide will test a simple indexer that records Transfer events into a
database table. The code for the indexer is the following:
import { hash, uint256 } from "https://esm.run/[email protected]";
import { formatUnits } from "https://esm.run/[email protected]";
const DECIMALS = 18;
export const config = {
streamUrl: "https://sepolia.starknet.a5a.ch",
startingBlock: 10_000,
network: "starknet",
filter: {
header: { weak: true },
events: [
{
fromAddress:
"0x03e85bfbb8e2a42b7bead9e88e9a1b19dbccf661471061807292120462396ec9",
keys: [hash.getSelectorFromName("Transfer")],
},
],
},
sinkType: "postgres",
sinkOptions: {
tableName: "transfers",
},
};
export default function transform({ header, events }) {
const { blockNumber, blockHash, timestamp } = header;
return events.map(({ event, receipt }) => {
const { transactionHash } = receipt;
const transferId = `${transactionHash}_${event.index}`;
const [fromAddress, toAddress, amountLow, amountHigh] = event.data;
const amountRaw = uint256.uint256ToBN({ low: amountLow, high: amountHigh });
const amount = formatUnits(amountRaw, DECIMALS);
// Convert to snake_case because it works better with postgres.
return {
network: "starknet-sepolia",
symbol: "ETH",
block_hash: blockHash,
block_number: +blockNumber,
block_timestamp: timestamp,
transaction_hash: transactionHash,
transfer_id: transferId,
from_address: fromAddress,
to_address: toAddress,
amount: amount,
amount_raw: amountRaw.toString(),
};
});
}We can generate a snapshot by running the apibara test command. Since the
testing tool connects to the live DNA stream to create the test fixtures, we
must pass an authentication token with the -A flag or the AUTH_TOKEN
environment variable. The snapshots are generated in the current directory's
snapshots/ folder.
apibara test transfers.js -A dna_xxxGenerating snapshot `snapshots/transfers.json` ...
Generated snapshot successfully with 1 batch (799999 -> 800000)
We can inspect the snapshot, which is a JSON file with the following properties:
scriptPath: the path to the script under test.numBatches: batch size used to generate the test.streamOptions: contains the URL of the stream used to create the test data.streamConfigurationOptions: options returned in theconfigobject from the script. These options are compared between reruns to detect any changes.testOptions: options related to testing. See the options page to learn about the available options.stream[].input: input stream data generated by connecting to a DNA stream.stream[].output: values returned by applying the indexer transform function to the input data.
Notice how, by default, the snapshot includes data only for one block. Later in this guide, we will learn how to control which blocks are included when generating the snapshot.
For this tutorial's sake, we want the amount field to be the tokens
transferred and stored as a floating point number. If we inspect the snapshot
file, we see that this value is stored as a string. We have two equivalent
strategies to update our code and the snapshot:
- Manually update the snapshot file by replacing the string value with a floating point value.
- Update the indexer code and overwrite the snapshot.
In this guide, we are going to adopt the second strategy. Let's start by updating the indexer code.
diff --git a/src/transfers.js b/src/transfers.js
index 67f64ac..cf37d84 100644
--- a/src/transfers.js
+++ b/src/transfers.js
@@ -43,7 +43,7 @@ export default function transform({ header, events }) {
transfer_id: transferId,
from_address: fromAddress,
to_address: toAddress,
- amount: amount,
+ amount: +amount,
amount_raw: amountRaw.toString(),
};
});If we run apibara test now, the test fails because
the indexer output doesn't match the snapshot file.
Notice how Apibara highlights the differences between the expected and actual
outputs.
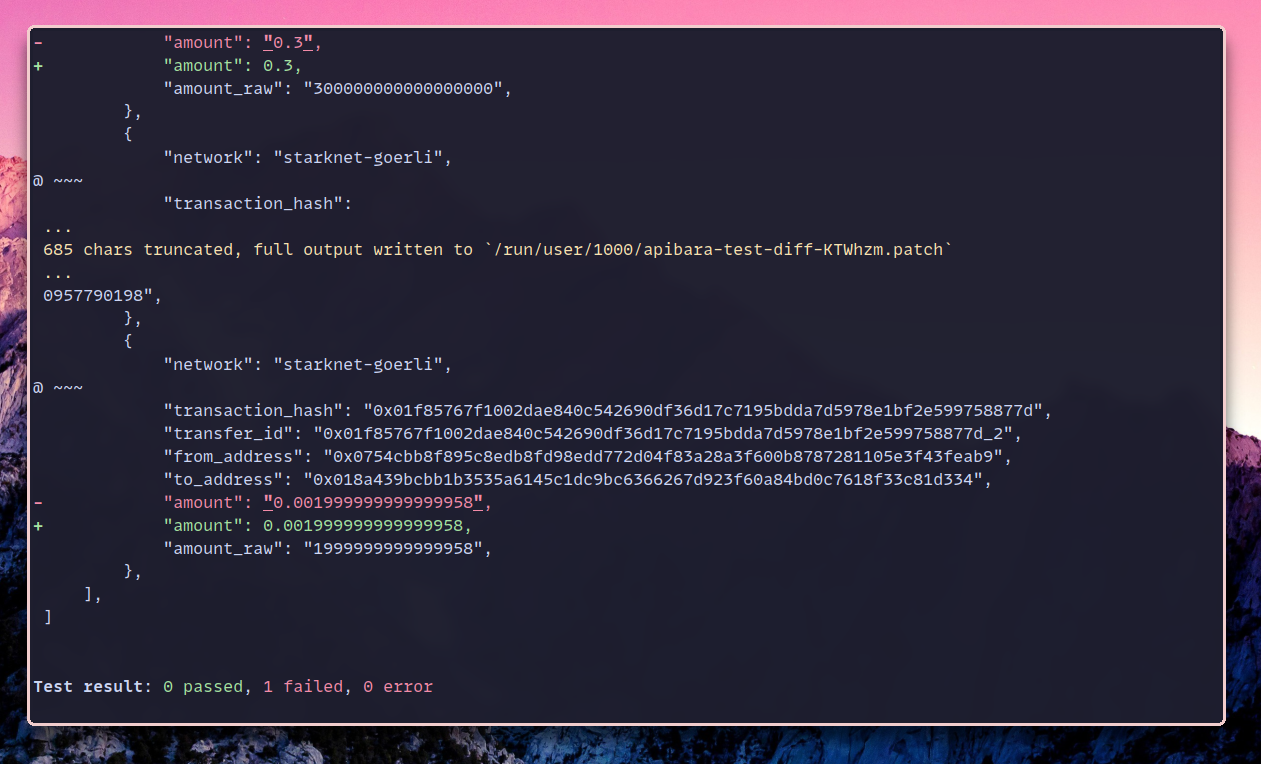
We can overwrite the snapshot file with the --override flag.
apibara test transfers.js -A dna_xxx --overrideGenerating snapshot `snapshots/transfers.json` ...
Generated snapshot successfully with 1 batch (799999 -> 800000)
After re-creating the snapshot, we can re-run apibara test and
it will succeed.
apibara testCollecting tests for `src/transfers.js` from `snapshots` ...
Collected 1 files
Running test `snapshots/transfers.json` ...
Test passed
Test result: 1 passed, 0 failed, 0 error
More complex indexers handle several types of events, so testing them on a
single block is impractical. The test command provides the following flags to
help you create better tests:
--name(-n): give the specified name to the test, for examplezero_amounts_are_skipped.--starting-block(-s): change the starting block used to generate the fixtures.--num-batches(-b): collect the specified number of batches of data from the DNA stream.
Handling floating point numbers
In this tutorial, we stored the transfers' amounts as floating point numbers. Most of the times, this is fine. Sometimes, this could cause issues when comparing the expected with the actual snapshot because of the loss of precision caused by floating point numbers.
If that's the case, you can change the testOptions.floatingPointDecimals
option in the snapshot to set the number of decimal places used when comparing
two floating point numbers.
Running in a CI
The apibara test command is perfect for testing indexers in a continuous
integration (CI) environment like GitHub actions. Running apibara test will
run all tests in the snapshot/ folder by replaying the data in the snapshot.
For this reason, you do not need to expose the DNA auth token in the test
environment.
Best practices
Snapshot tests are a powerful tool. You should follow these best practices to get the most out of them.
Indexers should be deterministic
Apibara encourages indexers to be fully deterministic. This means using only data derived from the block's content. Determinism is essential for indexers because we want data to be path-independent: data stored in our target integration should not depend on when the indexer was run. For example, an indexer deployed two weeks ago should produce the same data as the indexer deployed today.
Review onchain data
You should continuously review real-world onchain data generated by your application. Whenever you find a bug in production, you should create a new test case using the block that triggered the bug. This also ensures that no regressions make it to production.
Review snapshot changes
Treat snapshots as code when you review pull requests.